Semantic Segmentation
이전에 작성한 포스팅을 기반으로 Semantic Segmentation 모델을 직접 구현해볼 것이다.
데이터셋은 Pascal VOC 2012을 이용할 것이다.

Pascal VOC 데이터셋은 Computer Vision 연구 커뮤니티에서 널리 사용되는 대표적인 벤치마크 데이터셋 중 하나이다. 주로 Object Detection, Classification, Segmentation Task 등에 사용된다.
영국의 Pascal(Pattern Analysis, Statistical Modelling and Computational Learning) 네트워크에 의해 2005년부터 2012년까지 매년 한 번씩 발표되었다.
Pascal VOC 2012는 Pascal VOC 2007과 동일하게 20개의 Object Class를 가지고 있지만, 복잡한 장면들이 추가되었으므로 더 큰 규모를 가진다.
이번 포스팅에서 할 Task는 Semantic Segmentation이므로 아래처럼 Segmentation Mask 파일들을 추가로 Load 해줘야 한다.

Pixel-wise Classification
Import
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
import cv2
import numpy as np
import functions
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
function.py 또한 import 했는데, 이는 Segmentation 수행을 위한 여러 함수들이 포함된 파일이다. 이미지 처리, 데이터 전처리, 모델 평가 등을 위한 함수들이 있다. 자세한 내용은 주석을 통해 설명할 것이다.
코드 내용은 아래와 같다.
function.py
from PIL import Image
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
import random
import os
"""
bilinear upsampling에 사용할 가중치 필터 생성 함수
"""
def get_upsampling_weight(in_channels, out_channels, kernel_size):
# 커널 크기에 따른 스케일링 팩터 계산 (커널 크기의 중간 값)
factor = (kernel_size + 1) // 2
# 커널 크기가 홀수일 경우 중앙값 결정, 짝수일 경우 중앙을 반으로 나누어 결정
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 커널 크기의 좌표 격자 생성
og = np.ogrid[:kernel_size, :kernel_size]
# 격자와 스케일링 팩터를 사용해 bilinear 필터 계산
filt = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
# 입력 채널과 출력 채널에 해당하는 필터 생성 (채널별로 필터를 적용)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size),
dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
# NumPy 배열을 PyTorch 텐서로 변환하여 반환
return torch.from_numpy(weight).float()
"""
Segmentation Mask를 시각화 가능한 RGB 이미지로 변환하는함수
"""
def segmentation_output(mask, num_classes=21):
# 각 클래스(0~20)에 대한 색상 값 미리 정의
# 이때 클래스가 21개인 이유는 background인 경우를 포함하기 때문
# 0=background
# 1=aeroplane, 2=bicycle, 3=bird, 4=boat, 5=bottle
# 6=bus, 7=car, 8=cat, 9=chair, 10=cow
# 11=diningtable, 12=dog, 13=horse, 14=motorbike, 15=person
# 16=potted plant, 17=sheep, 18=sofa, 19=train, 20=tv/monitor
label_colours = [
(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (64, 0, 0),
(128, 0, 128), (0, 128, 128), (128, 128, 128), (0, 0, 128), (192, 0, 0),
(64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128), (64, 128, 128),
(192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0),
(0, 64, 128)
]
# mask의 높이(h)와 너비(w)를 가져옴
h, w = mask.shape
# 새로운 RGB 이미지를 mask 크기만큼 생성
img = Image.new('RGB', (w, h))
pixels = img.load() # 픽셀 접근을 위해 load() 함수 사용
# mask의 각 픽셀 값을 확인하여 해당 클래스에 맞는 색상으로 변환
for j_, j in enumerate(mask[:, :]):
for k_, k in enumerate(j):
if k < num_classes: # 클래스가 num_classes 이하일 때만 색상 적용
pixels[k_, j_] = label_colours[k] # 클래스에 해당하는 색상으로 픽셀 설정
# 최종적으로 색상 적용된 이미지를 NumPy 배열로 변환하여 반환
output = np.array(img)
return output
"""
경로를 입력 받아 경로 내의 이미지 파일 목록을 읽어오는 함수
"""
def read_file(path_to_file):
# 주어진 파일 경로에서 텍스트 파일을 열어 각 줄을 리스트로 읽어옴
with open(path_to_file) as f:
img_list = []
# 각 줄을 순차적으로 읽고 끝에 있는 줄바꿈 문자를 제거한 후 리스트에 추가
for line in f:
img_list.append(line[:-1])
return img_list # 이미지 목록 리스트 반환
"""
주어진 리스트(seq)를 일정한 크기(size)로 나누어 청크로 반환해주는 함수
"""
def chunker(seq, size):
return (seq[pos:pos + size] for pos in range(0, len(seq), size))
"""
주어진 확률(flip_p)에 따라 이미지를 좌우 반전해주는 함수(데이터 증강)
"""
def flip(I, flip_p):
# flip_p 값이 0.5보다 크면 이미지 좌우 반전(fliplr) 적용
if flip_p > 0.5:
return np.fliplr(I)
else:
return I # 그렇지 않으면 원래 이미지를 반환
"""
이미지를 주어진 scale 값에 맞춰 크기를 조정해주는 함수
"""
def scale_im(img_temp, scale):
# 이미지의 새로운 크기를 스케일 비율에 맞춰 계산
new_dims = (int(img_temp.shape[0] * scale), int(img_temp.shape[1] * scale))
# OpenCV의 resize 함수를 이용해 이미지 크기 조정 후 반환
return cv2.resize(img_temp, new_dims).astype(float)
"""
주어진 이미지와 그에 해당하는 gt(ground truth)를 불러와 전처리 해주는 함수
"""
def get_data(chunk, gt_path='./dataset/gt', img_path='./dataset/img'):
# 입력으로 받은 chunk의 길이가 1인지 확인 (assert)
assert len(chunk) == 1
# 이미지 증강을 위한 랜덤 스케일과 좌우 반전 확률(flip_p) 설정
scale = random.uniform(0.5, 1.3)
flip_p = random.uniform(0, 1)
# 이미지 파일을 읽어옴 (이미지 경로는 img_path와 chunk 값 사용)
images = cv2.imread(os.path.join(
img_path, chunk[0] + '.jpg')).astype(float)
# 이미지를 321x321 크기로 리사이즈
images = cv2.resize(images, (321, 321)).astype(float)
# 이미지를 스케일에 맞게 다시 크기 조정
images = scale_im(images, scale)
# RGB 이미지의 평균값을 빼서 정규화 (일반적으로 사용하는 값)
images[:, :, 0] = images[:, :, 0] - 104.008
images[:, :, 1] = images[:, :, 1] - 116.669
images[:, :, 2] = images[:, :, 2] - 122.675
# 확률에 따라 이미지를 좌우 반전
images = flip(images, flip_p)
# 이미지에 새로운 축을 추가하고, 텐서 형태로 변환 (배치, 채널, 높이, 너비)
images = images[:, :, :, np.newaxis]
images = images.transpose((3, 2, 0, 1))
images = torch.from_numpy(images.copy()).float()
# Ground Truth(정답 라벨) 이미지를 읽어옴 (png 파일)
gt = cv2.imread(os.path.join(gt_path, chunk[0] + '.png'))[:, :, 0]
gt[gt == 255] = 0 # 라벨에서 255인 값은 0으로 변경 (배경 처리)
# Ground Truth 이미지도 확률에 따라 좌우 반전
gt = flip(gt, flip_p)
# Ground Truth 이미지도 스케일에 맞춰 리사이즈 (Nearest Neighbor 방식 사용)
dim = int(321 * scale)
gt = cv2.resize(
gt, (dim, dim), interpolation=cv2.INTER_NEAREST).astype(float)
# 라벨 데이터를 새로운 축을 추가하여 반환
labels = gt[np.newaxis, :].copy()
return images, labels # 이미지와 라벨 반환
"""
Model의 성능을 평가하기 위해 mIoU를 계산하는 함수
"""
def validation_miou(model):
# 클래스 최대 수 설정
max_label = 20
hist = np.zeros((max_label + 1, max_label + 1))
# 빠른 히스토그램 계산을 위한 내부 함수 정의
def fast_hist(a, b, n):
# 유효한 범위 내의 클래스들만 선택
k = (a >= 0) & (a < n)
# 두 배열의 히스토그램 계산 (a와 b의 조합)
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
# 검증 데이터 리스트 파일을 읽어옴
val_list = open('./dataset/list/val.txt').readlines()
print('mIoU calculation start')
with torch.no_grad(): # 그래디언트 계산 비활성화 (검증 단계)
for idx, i in enumerate(val_list):
# 이미지를 읽어와 전처리 (평균값 빼기)
img = cv2.imread(os.path.join('./dataset/img', i[:-1] + '.jpg')).astype(float)
img[:, :, 0] -= 104.008
img[:, :, 1] -= 116.669
img[:, :, 2] -= 122.675
# 이미지를 PyTorch 텐서로 변환하고 모델에 입력
data = torch.from_numpy(img.transpose((2, 0, 1))).float().cuda().unsqueeze(0)
score = model(data)
# 모델 예측 결과를 얻고, 클래스별로 argmax 계산
output = score.cpu().data[0].numpy().transpose(1, 2, 0)
output = np.argmax(output, axis=2)
# Ground Truth 이미지를 읽어옴
gt = cv2.imread(os.path.join('./dataset/gt', i[:-1] + '.png'), 0)
# 예측 결과와 Ground Truth로 히스토그램 업데이트
hist += fast_hist(gt.flatten(), output.flatten(), max_label + 1)
# 각 클래스별 mIoU 계산
miou = np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))
print("mIoU = ", np.sum(miou) / len(miou))
return np.sum(miou) / len(miou) # 평균 mIoU 반환
Test Image
Test Image로 사용할 이미지 하나를 데이터셋 폴더 내에서 선택한다.
img_path = './dataset/img/2007_009889.jpg'
test_img = Image.open(img_path)
test_img
Test Image Preprocessing
Test Image를 전처리해준다.
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ImageNet 데이터셋의 이미지들의 RGB의 평균과 표준편차 값
transform = transforms.Compose([
transforms.Resize(256), # Resizing
transforms.CenterCrop(224), # Crop
transforms.ToTensor(), # To tensor
normalize,
])
test_transform = transform(test_img).cuda().unsqueeze(0)
# Padding
m = nn.ZeroPad2d((111,112,111,112))
pad_image = m(test_transform)
img_1by1 = torch.zeros((224,224)).cuda()
VGG-NET Load & Pixel Classification
VGG16의 파라미터들을 Loading 한 후 이를 기반으로 Pixel 연산을 수행한다.
test_model = vgg.vgg16(pretrained=True).cuda()
for i in range(224):
for j in range(224):
patch = pad_image[:,:,i:i+224,j:j+224]
# classify each pixels
with torch.no_grad():
img_1by1[i,j] = torch.argmax(test_model(patch))
plt.subplot(1,2,1)
plt.imshow(test_transform[0].data.cpu().numpy().transpose((1,2,0)))
plt.subplot(1,2,2)
plt.imshow(img_1by1.data.cpu().numpy())
plt.show()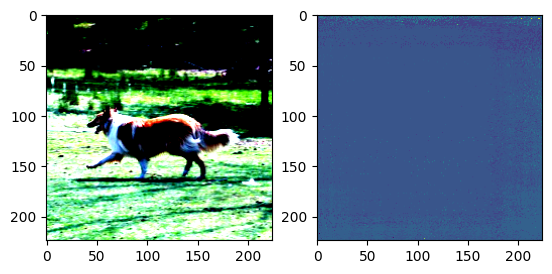
성능이 제대로 나오지 않는 것을 볼 수 있다.
그러므로 다른 방법을 시도해볼 필요가 있다.
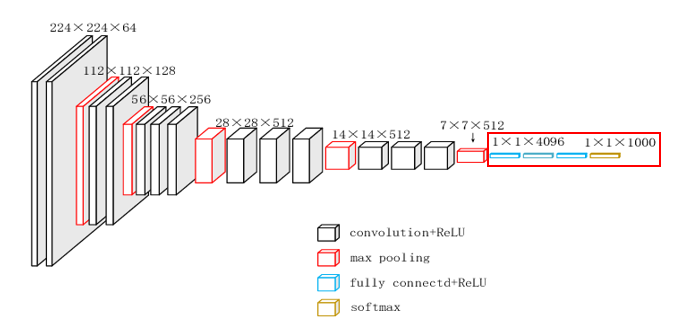
Upsampling과 Downsampling 과정 없이 VGG16의 마지막 Fully Connected Layer를 Convolutional Layer로 대체하여 볼 것이다.
class VGG_only_Convolution(nn.Module):
def __init__(self):
super(VGG_only_Convolution, self).__init__()
self.features = models.vgg16(pretrained=True).features
# Convolutional Layer
self.fc6 = nn.Conv2d(512, 4096, 7)
self.fc7 = nn.Conv2d(4096, 4096, 1)
self.fc8 = nn.Conv2d(4096, 1000, 1)
# ReLU
self.relu = nn.ReLU(inplace=True)
# Dropout
self.dropout = nn.Dropout2d()
self.copy_params_from_vgg16()
def forward(self, x):
conv5 = self.features(x)
fc6 = self.relu(self.fc6(conv5))
fc7 = self.dropout(fc6)
fc7 = self.relu(self.fc7(fc7))
fc8 = self.dropout(fc7)
score = self.fc8(fc8)
return score
# pre-train된 VGG16 Model의 매개변수 복사
def copy_params_from_vgg16(self):
vgg16 = models.vgg16(pretrained=True)
for i, name in zip([0, 3, 6], ['fc6', 'fc7', 'fc8']):
l1 = vgg16.classifier[i]
l2 = getattr(self, name)
l2.weight.data.copy_(l1.weight.data.view(l2.weight.size()))
l2.bias.data.copy_(l1.bias.data.view(l2.bias.size()))
test_model = VGG_only_Convolution().cuda()
transform_conv = transforms.Compose([
transforms.ToTensor(),
normalize,
])
test_conv = transform_conv(test_img).cuda().unsqueeze(0)
conv_out = test_model(test_conv)
pred = torch.argmax(conv_out, dim=1)
predtensor([[[231, 231, 231, 231, 231, 231, 231, 255, 255],
[231, 231, 231, 231, 231, 231, 231, 231, 231],
[231, 231, 231, 231, 231, 231, 231, 231, 177],
[231, 231, 231, 231, 231, 231, 231, 231, 231],
[231, 231, 231, 231, 231, 231, 231, 231, 231]]], device='cuda:0')
tensor 형태의 결과를 보면, 이 또한 그다지 좋지 못한 성능을 보이는 것을 확인할 수 있다.
그러므로 Bilinear Interpolation 방법을 사용해볼 것이다.
Upsampling with Bilinear Interpolation
Model의 마지막 Layer에 Bilinear Interpolation을 위한 Layer를 추가해줄 것이다.
Bilinear Interpolation은 Pytorch 라이브러리를 이용하여 사용할 수 있다.
Model
class bilinear_upsampled_VGG16(nn.Module):
def __init__(self):
super(bilinear_upsampled_VGG16, self).__init__()
self.features = models.vgg16(pretrained=True).features
self.features[0].padding = (100,100) # 이미지 크기를 맞추기 위한 패딩 설정
# fc6
self.fc6 = nn.Conv2d(512, 4096, 7)
# fc7
self.fc7 = nn.Conv2d(4096, 4096, 1)
# fc8
# Pascal VOC 2012의 Class를 맞춰주기 위해 output channel을 21로 설정
# 채널의 수가 21인 이유는 이미지 내에 객체가 존재하지 않는(only background)경우를 추가했기 때문
self.fc8 = nn.Conv2d(4096, 21, 1)
# ReLU
self.relu = nn.ReLU(inplace=True)
# Dropout
self.dropout = nn.Dropout2d()
# scaling factor = 32, Upsampling with Bilinear Interpolation Layer 정의
self.upsample = nn.Upsample(scale_factor=32, mode='bilinear', align_corners=True)
# pre-train된 VGG16 Model의 매개변수 복사를 위한 코드
self.copy_params_from_vgg16()
def forward(self, x):
conv5 = self.features(x)
fc6 = self.relu(self.fc6(conv5))
fc7 = self.dropout(fc6)
score = self.fc8(fc7)
input_size = x.size()[2:] # 입력 크기(높이, 너비)저장
upsampled_score = self.upsample(score)
# upsampled_score의 크기를 입력 크기와 일치하도록 조정
upsampled_score = nn.functional.interpolate(upsampled_score, size=input_size, mode='bilinear', align_corners=True)
return upsampled_score
def copy_params_from_vgg16(self): # pre-train된 VGG16 Model의 매개변수를 복사하는 함수
vgg16 = models.vgg16(pretrained=True)
for i, name in zip([0, 3], ['fc6', 'fc7']):
l1 = vgg16.classifier[i]
l2 = getattr(self, name)
l2.weight.data.copy_(l1.weight.data.view(l2.weight.size()))
l2.bias.data.copy_(l1.bias.data.view(l2.bias.size()))
"self.upsample = nn.Upsample(scale_factor=32, mode='bilinear', align_corners=True)"에서 scale_factor를 32로 설정하는 이유는 Model의 출력을 Input Image의 본래 크기로 복원하기 위해서이다.
VGG16 모델은 5개의 Pooling Layer를 통해 Input Image의 크기를 줄이면서 크기를 추출하기 때문에 Image의 크기가 1/5로 줄어든다.
따라서 본래의 Input Image 크기로 복원하기 위해 scale_factor를 32로 설정한다.
Model Load & Prediction
bilinear_upsample = bilinear_upsampled_VGG16().cuda()
model_data = torch.load('./bilinear_upsampled_VGG16.pth')
bilinear_upsample.load_state_dict(model_data)with torch.no_grad():
conv_out = bilinear_upsample(test_conv)
output = torch.argmax(conv_out, dim=1)
vis_output = functions.segmentation_output(output[0].data.cpu().numpy())
plt.subplot(1,2,1)
plt.imshow(test_conv[0].data.cpu().numpy().transpose((1,2,0)))
plt.subplot(1,2,2)
plt.imshow(vis_output)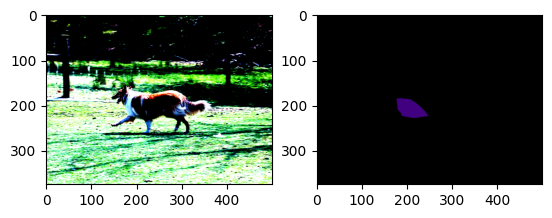
어느정도는 Segmentation이 된 것을 볼 수 있다. 하지만 더 나은 결과를 위해 다른 방법을 시도해볼 필요가 있다.
CNN model with Encoder/Decoder Structure
해당 포스팅에서는 Encoder와 Decoder를 가진 CNN Model인 FCN-8s(Fully Convolutional Network with 8-stride)을 구현해볼 것이다.
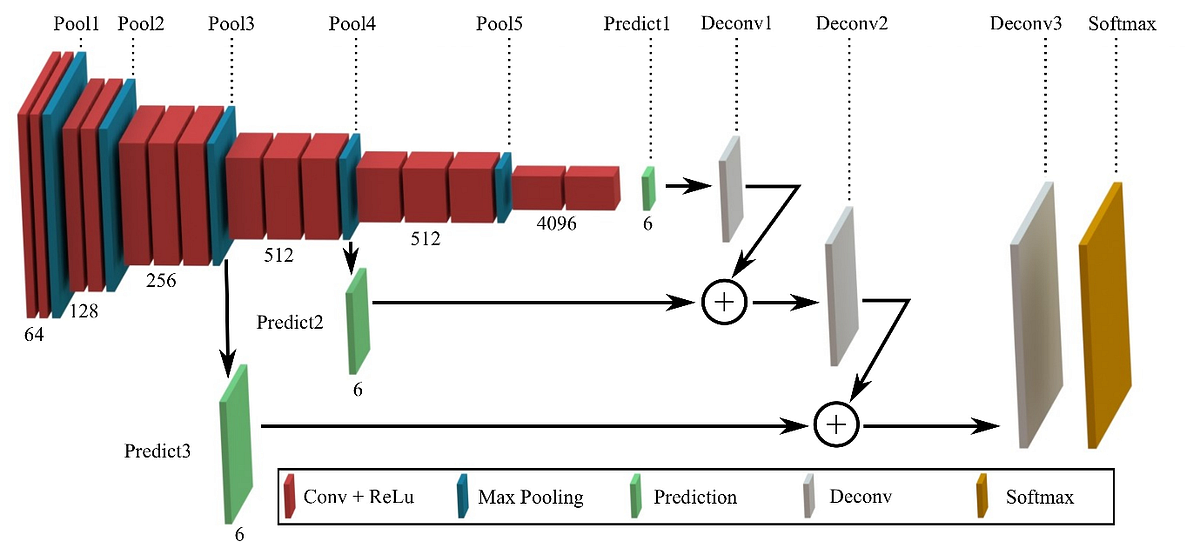
FCN-8s은 기존의 VGG16 Network를 기반으로 구축되었으며, 기존의 Fully Connected Layer들을 Convolutional Layer들로 대체하였기 때문에 위치 정보를 유지하며 특징 추출이 가능하다.
이때 Skip Connection 기법을 위해 Convolutinal Layer 기반의 Predict Layer 3개를 구현해줄 것이다.
Model
class FCN8s(nn.Module):
def __init__(self, n_class=21):
super(FCN8s, self).__init__()
self.features = models.vgg16(pretrained=True).features
# fc6 layer
self.fc6 = nn.Conv2d(512, 4096, 7)
# fc6 layer
self.fc7 = nn.Conv2d(4096, 4096, 1)
# ReLU
self.relu = nn.ReLU(inplace=True)
# Dropout
self.dropout = nn.Dropout2d()
# 각 단계에 대한 prediction convolutions 정의
self.predict_conv1 = nn.Conv2d(4096, n_class, kernel_size=1)
self.predict_conv2 = nn.Conv2d(512, n_class, kernel_size=1)
self.predict_conv3 = nn.Conv2d(256, n_class, kernel_size=1)
# Upsampling을 위한 Deconvolution layer를 정의
self.deconv1 = nn.ConvTranspose2d(n_class, n_class, kernel_size=4, stride=2, bias=False)
self.deconv2 = nn.ConvTranspose2d(n_class, n_class, kernel_size=4, stride=2, bias=False)
self.deconv3 = nn.ConvTranspose2d(n_class, n_class, kernel_size=16, stride=8, bias=False)
self._initialize_weights()
self.copy_params_from_vgg16()
def _initialize_weights(self):
self.features[0].padding = (100,100)
# MaxPool2d layer, ConvTranspose2d layer 초기화
for m in self.modules():
if isinstance(m, nn.MaxPool2d):
m.ceil_mode = True
if isinstance(m, nn.ConvTranspose2d):
assert m.kernel_size[0] == m.kernel_size[1]
initial_weight = functions.get_upsampling_weight(
m.in_channels, m.out_channels, m.kernel_size[0])
m.weight.data.copy_(initial_weight)
def forward(self, x):
initial = x
# VGG 네트워크를 통과시키고, pool3와 pool4의 결과를 저장한다.
for idx, layer in enumerate(self.features):
x = layer(x)
if idx == 16:
pool3 = x.clone()
elif idx == 23:
pool4 = x.clone()
# Pass through fc6 layer
x = self.dropout(self.relu(self.fc6(x)))
# Pass through fc7 layer
x = self.dropout(self.relu(self.fc7(x)))
# Pass through Prediction 1 and Deconvolution 1
x = self.predict_conv1(x)
x = self.deconv1(x)
deconv1 = x
# Pass through Prediction 2
x = self.predict_conv2(pool4)
x = x[:, :, 5:5 + deconv1.size(2), 5:5 + deconv1.size(3)] # Crop boundary
predict2 = x
# Add deconv1 and predict2, then pass through Deconvolution 2
x = deconv1 + predict2 * 0.01
x = self.deconv2(x)
deconv2 = x
# Pass through Prediction 3
x = self.predict_conv3(pool3)
x = x[:, :, 9:9 + deconv2.size(2), 9:9 + deconv2.size(3)] # Crop boundary
predict3 = x
# Add predict3 and deconv2
x = predict3 * 0.0001 + deconv2
# Pass through Deconvolution 3
x = self.deconv3(x)
x = x[:, :, 31:31+initial.size(2), 31:31+initial.size(3)].contiguous() # Crop boundary
return x
def copy_params_from_vgg16(self): # pre-train된 VGG16 Model의 매개변수를 복사하는 함수
vgg16 = models.vgg16(pretrained=True)
for i, name in zip([0, 3], ['fc6', 'fc7']):
l1 = vgg16.classifier[i]
l2 = getattr(self, name)
l2.weight.data.copy_(l1.weight.data.view(l2.weight.size()))
l2.bias.data.copy_(l1.bias.data.view(l2.bias.size()))model = FCN8s().cuda()
Dataset Load & Shuffle
경로에서 이미지를 읽어와 랜덤하게 섞은 후, 이를 작은 청크로 나눈다.
img_list = functions.read_file('./dataset/list/train_aug.txt')
data_list = []
for i in range(10):
np.random.shuffle(img_list)
data_list.extend(img_list)
data_gen = functions.chunker(data_list, 1)
Train
lr = 0.00001
optimizer = optim.Adam(model.parameters(), lr=lr)
optimizer.zero_grad()
criterion = nn.CrossEntropyLoss() # cross-entropy loss 함수 사용
max_iter = 30000
Learning rate = 0.00001
Optimizer = Adam
Loss Function = CrossEntrophy
Iteration = 40000
으로 설정한다.
running_loss = 0.0
for iter in range(max_iter + 1):
inputs, label = functions.get_data(next(data_gen))
# training loop
model.train()
inputs = torch.tensor(inputs).cuda()
label = torch.tensor(label).long().cuda()
optimizer.zero_grad()
output = model(inputs)
loss = criterion(output, label)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (iter % 100 == 0) & (iter != 0):
print(f'Iteration: {iter}, Loss: {running_loss / (iter+1)}')Iteration: 100, Loss: 2.7233310846408996
Iteration: 200, Loss: 2.1845591014149175
Iteration: 300, Loss: 1.9665549208357485
Iteration: 400, Loss: 1.8524811884337233
Iteration: 500, Loss: 1.7750985584632604
Iteration: 600, Loss: 1.7075675491882045
Iteration: 700, Loss: 1.6549173662606387
Iteration: 800, Loss: 1.626530836025874
Iteration: 900, Loss: 1.597206949377298
Iteration: 1000, Loss: 1.571184472805196
Iteration: 1100, Loss: 1.525258448912164
Iteration: 1200, Loss: 1.4952326772314226
Iteration: 1300, Loss: 1.4730863277897022
Iteration: 1400, Loss: 1.4461032710676955
Iteration: 1500, Loss: 1.4152935786491667
...
Iteration: 37900, Loss: 0.5610974585407918
Iteration: 38000, Loss: 0.5607748318492165
Iteration: 38100, Loss: 0.5603357465116652
Iteration: 38200, Loss: 0.5599884153777814
Iteration: 38300, Loss: 0.5595342107939296
Iteration: 38400, Loss: 0.5591732920463853
Iteration: 38500, Loss: 0.5586533581206954
Iteration: 38600, Loss: 0.558243431043452
Iteration: 38700, Loss: 0.5577734231303489
Iteration: 38800, Loss: 0.5574485133421132
Iteration: 38900, Loss: 0.5570583450290141
Iteration: 39000, Loss: 0.5564972565181442
Iteration: 39100, Loss: 0.5560030190277739
Iteration: 39200, Loss: 0.5555181937426069
Iteration: 39300, Loss: 0.5550355939235556
Iteration: 39400, Loss: 0.5545707341337074
Iteration: 39500, Loss: 0.5541460120050852
Iteration: 39600, Loss: 0.5536971499559747
Iteration: 39700, Loss: 0.5532972731153828
Iteration: 39800, Loss: 0.5529683559026373
Iteration: 39900, Loss: 0.5524419323230301
Iteration: 40000, Loss: 0.5519264281773543
mIoU Calculation
FCN-8s Model과 Bilinear Interpolation만을 사용한 Model의 mIoU를 계산한다.
FCN-8s Model의 mIoU가 더 높아야 할 것이다.
fcn8s_miou = functions.validation_miou(model)
bilinearVgg_miou = functions.validation_miou(bilinear_upsample)mIoU Calculation Start
mIoU = 0.5054866001277657
mIoU Calculation Start
mIoU = 0.4402741312695869
print('FCN-8s의 mIoU =', fcn8s_miou)
print('bilinear로 upsample된 Model의 mIoU =', bilinearVgg_miou)FCN-8s의 mIoU = 0.5054866001277657
bilinear로 upsample된 모델의 mIoU = 0.4402741312695869
FCN-8s Model의 mIoU가 더 높은 것을 확인할 수 있다.
Prediction
with torch.no_grad():
conv_out_model = model(test_conv)
output_model = torch.argmax(conv_out_model, dim=1)
vis_output_model = functions.segmentation_output(output_model[0].data.cpu().numpy())
plt.subplot(1,2,1)
plt.imshow(test_conv[0].data.cpu().numpy().transpose((1,2,0)))
plt.subplot(1,2,2)
plt.imshow(vis_output_model)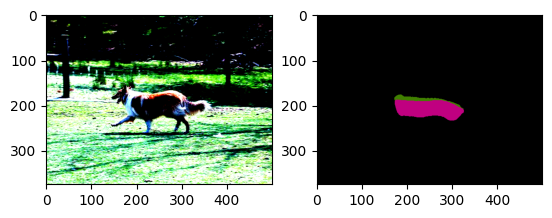
2개의 객체가 존재한다고 Segmentation 하긴 했지만
Bilinear Interpolation만을 적용한 Model보다 더 나은 성능을 보이는 것을 확인할 수 있다.
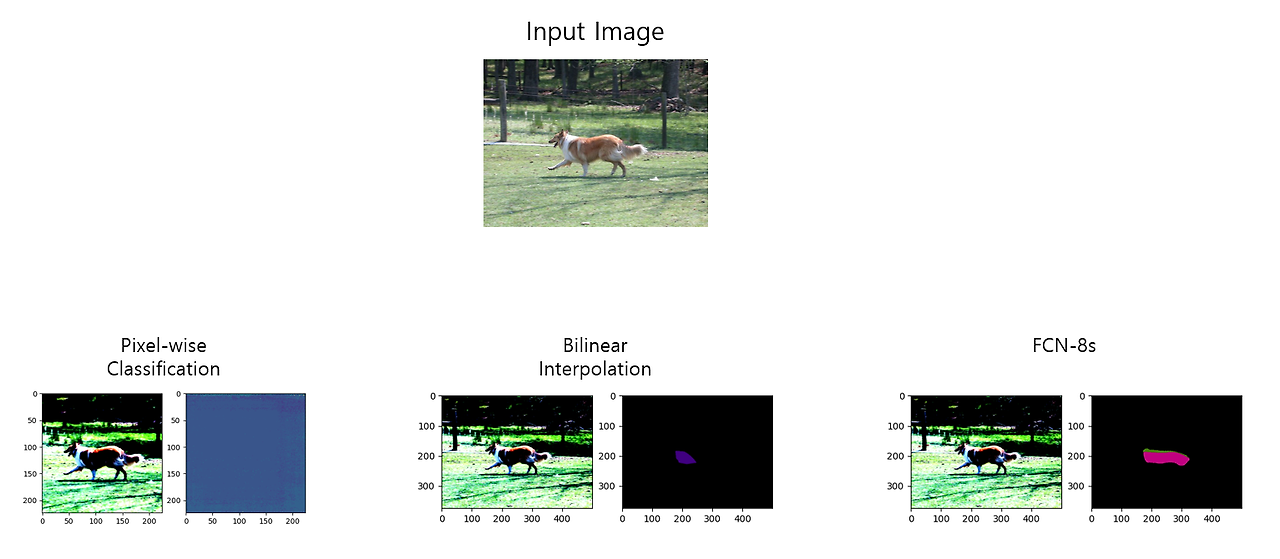
마지막으로, 3개의 방법의 결과들을 비교한 그림은 아래와 같다.
'딥러닝' 카테고리의 다른 글
| [Pytorch] RNN(Recurrent Neural Network) (6) | 2024.10.18 |
|---|